队列(Queue)也是常用的数据结构之一。在JDK中提供了一个ConcurrentLinkedQueue类用来实现高并发的队列。从名字可以看出,这个队列是使用链表作为其数据的结构的。ConcurrentLinkedQueue应该算是在高并发的环境中性能最好的了。它之所以有很好的性能,是因为其内部复杂的实现。下面我们就来一探究竟,为何性能高?
ConcurrentLinkedQueue的介绍
ConcurrentLinkedQueue是一个基于链表的无界非阻塞队列,并且是线程安全的,它采用的是先进先出的规则,当我们增加一个元素时,它会添加到队列的末尾,当我们取一个元素时,它会返回一个队列头部的元素。
ConcurrentLinkedQueue原理探究
作为一个链表,自然需要定义有关链表内的节点,在ConcurrentLinkedQueue中,定义的节点Node核心如下:
1 static final class Node{ 2 volatile E item; 3 volatile Node next; 4 5 /** 6 * Constructs a node holding item. Uses relaxed write because 7 * item can only be seen after piggy-backing publication via CAS. 8 */ 9 Node(E item) {10 ITEM.set(this, item);11 }12 13 /** Constructs a dead dummy node. */14 Node() {}15 16 void appendRelaxed(Node next) {17 // assert next != null;18 // assert this.next == null;19 NEXT.set(this, next);20 }21 22 boolean casItem(E cmp, E val) {23 // assert item == cmp || item == null;24 // assert cmp != null;25 // assert val == null;26 return ITEM.compareAndSet(this, cmp, val);27 }28 }
其中 item是用来表示目标元素的。比如,但队列中存放String时,item就是String类型。字段next表示当前Node的下一个元素,这样每个Node就能环环相扣,串在一起了。
方法casItem()表示设置当前Node的item值。它需要两个参数,第一个参数为期望值,第二个参数为设置目标值。当当前值等于cmp期望值时,它就会将目标设置为val。这个方法使用了CAS操作。
head和tail
ConcurrentLinkedQueue内部有两个重要的字段head和tail,分别表示链表的头部和尾部,他们都是Node类型,对于head来说,它永远不会为null,并且通过head以及succ()后继方法一定能完整的遍历整个链表。对于tail来说,它自然应该表示队列的末尾。但ConcurrentLinkedQueue的内部实现非常复杂,它允许在运行时链表处于多个不同的状态。以tail来说,我们期望tail总是为链表的末尾,但实际上,tail的更新并不是及时的,而是可能会产生拖延现象。来看一下源码:
offer():将指定的元素插入队列的尾部
1 public boolean offer(E e) { 2 final Node newNode = new Node (Objects.requireNonNull(e)); 3 4 for (Node t = tail, p = t;;) { 5 Node q = p.next; 6 if (q == null) { 7 // p是最后一个节点 8 if (NEXT.compareAndSet(p, null, newNode)) { 9 if (p != t) // 每两次更新一下tail10 TAIL.weakCompareAndSet(this, t, newNode);11 return true;12 }13 // CAS竞争失败,再次尝试14 }15 else if (p == q)16 // 遇到哨兵节点,从head开始遍历17 //但是如果tail被修改,则使用tail(因为可能被修改正确了)18 p = (t != (t = tail)) ? t : head;19 else20 // 每两次更新后,确认tail更新21 p = (p != t && t != (t = tail)) ? t : q;22 }23 } 首先值得注意的是,这个方法没有任何的锁操作。线程安全完全由CAS操作和队列的算法来保证。整个方法的核心是for循环,这个循环没有出口,直到尝试成功,这也符合CAS的操作流程。当第一次加入元素时,由于队列为空,因此p.next为null。程序进入第8行,将p的next节点赋值为newNode也就是将新的元素加入到队列中。此时p==t成立,因此并不会执行第9行代码更新tail末尾,如果 NEXT.compareAndSet(p, null, newNode) 成功,程序直接返回,如果失败,则再进行一次循环尝试,直到成功。因此,增加一个元素后,tail并不会被更新。此时队列是这样的:
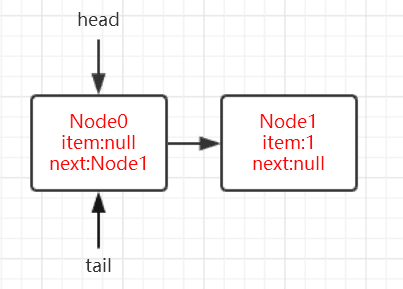
当程序试图增加第二个元素时,这时tail在head的位置上,因此t表示的就是head,所以p.next就是Node1(即第一个元素),此时q != null ,p != q ,所以程序进入else环节,运行第21行代码,获得最后一个节点,此时 p = q,即p指向链表的第一个元素Node1,开始第二个循环,p.next = null,所以程序执行第8行代码,p更新自己的next,让它指向新加入的节点,如果成功,此时 p != t 为true,这样就更新t的所在位置,将t移到链表的最后,即更新tail(这时tail才是链表的末尾)。
所以tail的更新会产生滞后,并且每两次会跳跃两个元素。如下图所示:

再来看代码的第15行,对p = q 的情况进行了处理;这种情况就属于遇到了哨兵节点导致的。所谓的哨兵节点就是next指向了自己。这种节点在队列中存在的价值不大,主要表示要删除的节点或者空节点,当遇到哨兵节点时,无法通过next取得后续的节点,通过代码第18行,很可能直接返回head,这样链表就会从头部开始遍历,重新查找到链表末尾。当然也有可能返回t,这样就进行了一次“打赌”,使用新的tail作为链表尾部(即t),这样避免了重新查找tail的开销。
对代码的第18行,进行分析: p = (t != (t = tail)) ? t : head
这句代码虽然只有一行,但是包含的信息比较多。首先“!=”不是原子操作,它是可以被中断的,也就是说,在执行“!=”时,程序会先取得t的值,在执行t = tail,并取得新的t的值,然后比较这两个值是否相等。在单线程中,t != t这种语句显然不会成立,但是在并发环境下,有可能在获得左边的t值后,右边的t值被其他线程修改,这样,t != t 就成立了。这种情况表示在比较的过程中,tail被其他线程修改了,这时,我们就用新的tail为链表的尾,也就是等式右边的t,但如果tail没有被修改,则返回head,要求从头部开始,重新查找链表末尾。
poll() :获取并移除队列的头,如果队列为空则返回null
先来看源代码:
1 public E poll() { 2 restartFromHead: for (;;) { 3 for (Node h = head, p = h, q;; p = q) { 4 final E item; 5 if ((item = p.item) != null && p.casItem(item, null)) { 6 // Successful CAS is the linearization point 7 // for item to be removed from this queue. 8 if (p != h) // hop two nodes at a time 9 updateHead(h, ((q = p.next) != null) ? q : p);10 return item;11 }12 else if ((q = p.next) == null) {13 updateHead(h, p);14 return null;15 }16 else if (p == q)17 continue restartFromHead;18 }19 }20 } 说明:poll()方法的作用就是删除链表的表头节点,并返回被删除节点的值。poll()的实现原理和offer()比较相似,下面对其分析:
代码的第5行表示:表头节点的数据不为null,并且设置表头数据为null的操作成功。然后进入if,如果 p != h 为true,则更新表头然后返回删除元素的值item,若为false,则直接返回删除元素的值,不更新表头。这点说明表头head也不是实时更新的,也是每两次更新一次(通过注释:hop two nodes at a time),跟tail的更新类似。
代码的第12行,表示表头的下一个节点为null,即链表只有一个内容为null的表头节点。这样则直接更新表头为p,返回null。
代码的第16行,当p == q 时,跳过当前循环,跳到restartFromHead标记重新操作。
即ConcurrentLinkedQueue的元素删除示意图如下所示:

ConcurrentLinkedQueue的其他方法:
peek():获取表头元素但不移除队列的头,如果队列为空则返回null。
remove(Object obj):移除队列已存在的元素,返回true,如果元素不存在,返回false。
add(E e):将指定元素插入队列末尾,成功返回true,失败返回false(此方法非线程安全的方法,不推荐使用)。
注意:
虽然ConcurrentLinkedQueue的性能很好,但是在调用size()方法的时候,会遍历一遍集合,对性能损害较大,执行很慢,因此应该尽量的减少使用这个方法,如果判断是否为空,最好用isEmpty()方法。
ConcurrentLinkedQueue不允许插入null元素,会抛出空指针异常。
ConcurrentLinkedQueue是无界的,所以使用时,一定要注意内存溢出的问题。即对并发不是很大中等的情况下使用,不然占用内存过多或者溢出,对程序的性能影响很大,甚至是致命的。
通过以上这些说明,可以明显的感觉到,不使用锁而单纯的使用CAS操作要求在应用层面上保证线程安全,并处理一些可能存在的不一致问题,大大增加了程序的设计和实现的难度。但是它带来的好处就是可以得到性能的飞速提升。因此,有些场合也是值得的。
参考:《Java高并发程序设计》 葛一鸣 郭超 编著: